Building a PDF Chat System with RAG: A Step-by-Step Implementation Guide
A practical guide to implementing Retrieval-Augmented Generation with local LLMs and vector search

Have you ever wished you could have a conversation with your PDF documents? In this comprehensive guide, we’ll build a PDF chat system from scratch using RAG (Retrieval-Augmented Generation) and local LLMs, creating an implementation we’ll call docuRAG.js.
By following along, you’ll learn to build a system that can process PDFs, understand their content, and answer questions accurately using the power of vector search and large language models. Grab your favorite code editor, and let’s dive into building something awesome!
What You’ll Learn
- How RAG systems work and why they’re powerful
- Step-by-step implementation of a PDF chat system
- Practical code examples you can use today
Required Services
- Local LLM Service (Ollama)
- Download and install Ollama
- Pull the Llama2 model:
ollama pull llama2 - Verify it’s running at
http://localhost:11434
2. Vector Database (Qdrant)
- Run using Docker:
docker run -p 6333:6333 qdrant/qdrant - Verify it’s running at
http://localhost:6333
What is RAG and Why Use It?
RAG (Retrieval-Augmented Generation) combines two powerful capabilities:
1. Retrieval: Finding relevant information in your documents
2. Generation: Creating human-like responses using an LLM
Instead of the LLM making things up, RAG helps it give accurate answers by first searching through your documents to find the most relevant information. It then uses these found passages as context, allowing the LLM to generate responses that are firmly grounded in your actual document content. This approach ensures that every answer is backed by real information from your documents.
The Implementation Journey
Let’s break this down into manageable steps. We’ll start with document processing and end with a working chat system.
1. Text Chunking: Document Segmentation
First, we need to read and process the PDF document. Let’s break this down into steps:
Reading the PDF
import pdfParse from 'pdf-parse';
async readPDFContent(pdfBuffer) {
const data = await pdfParse(pdfBuffer);
return data.text;
}Splitting into Chunks
We use langchain’s text splitter to break the document into manageable pieces while preserving context:
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
this.textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: this.config.chunkSize,
chunkOverlap: this.config.chunkOverlap,
lengthFunction: (text) => text.length,
});Let’s break down these parameters:
1. chunkSize (default: 1000): This is how many characters we want in each piece of text. Think of it like deciding how big each “bite” of the document should be. If it’s too big, the LLM might get overwhelmed. If it’s too small, we might lose important context. We found that 1000 characters gives us a good balance — about a paragraph or two.
2. chunkOverlap (default: 200): This is where we let chunks “share” some text with their neighbours. Imagine you’re reading a book and each chunk is a page — the overlap is like having the last few sentences of the previous page repeated at the start of the next page. This helps us not lose context when important information spans across chunks.
Here’s a simple example:
Original text: "The new AI model was developed in 2023.
It uses advanced neural networks."
Without overlap:
Chunk 1: "The new AI model was developed in 2023."
Chunk 2: "It uses advanced neural networks."
↓ We might miss the connection between the model and its technology! ↓
With overlap:
Chunk 1: "The new AI model was developed in 2023. It uses"
Chunk 2: "2023. It uses advanced neural networks."
Now we can connect the dots between the model and its features!2. Vector Embeddings: Making Text Searchable
To make our text chunks searchable, we need to convert them into a format that computers can efficiently process and compare. This is where vector embeddings come in.
What is vector embeddings?
Think of vector embeddings like turning words into numbers that computers can understand. These numbers are special because they capture not just the words, but also their meaning and how they relate to each other. So when we say “happy” and “joyful”, their number codes end up being very similar, just like their meanings!
Why do we need it?
Similar meanings get similar numbers (like how “happy” and “joyful” would be close to each other)
We can find related text by looking for similar number patterns, It’s much faster to search through numbers than actual text!
And here’s where the magic happens!
Let’s look at how these numbers help our system understand meaning, even when questions are asked differently:
Text: "The weather is really cold today"
↓
Vector: [0.4, 0.7, 0.3, …]
Similar question: "What's the temperature outside?"
↓
Vector: [0.38, 0.72, 0.28, …] <- Notice how these numbers are close
because the meanings are related!Converting Chunks to Vectors
With our understanding of vectors, we can now process each text chunk through the LLM’s embedding API:
const vector = await this.getEmbedding(chunk);3. Storing in Database
Now we can save both the text chunks and their vector representations in Qdrant. This creates a searchable knowledge base that we’ll query later when answering questions and save all these in the db
const vectors = await Promise.all(
chunks.map(async (chunk, index) => {
const embedding = await this.getEmbeddings(chunk);
return {
id: uuidv4(),
vector: embedding,
payload: { text: chunk, fileName: metadata.fileName, chunkIndex: index }
};
})
);
await this.qdrant.upsert(metadata.collectionName, {
points: vectors
});4. Building the Chat System
Now let’s put it all together into a working chat system:
Processing Chat Messages
When you send a chat message, the system follows a similar process to find and generate relevant answers:
1. Converting Your Question
First, we convert your question into a vector using the same embedding API. This allows us to search for similar content in our database.
Example: Processing a question
const question = "What are neural networks?";
const questionVector = await getEmbedding(question);Vector representing the question
Result: [0.45, 0.82, …]
2. Finding Relevant Information
We use this vector to search the database for chunks that are most similar to your question.
Search for similar chunks
const matches = await qdrant.search('my_collection', {
vector: questionVector,
limit: 3 // Get top 3 most relevant chunks
});Results:
[
{ text: "Neural networks are powerful algorithms…", score: 0.89 },
{ text: "Deep learning uses neural networks to…", score: 0.76 },
{ text: "Machine learning includes neural networks…", score: 0.71 }
]3. Generating the Answer
Finally, we send both your question and the found chunks from the db to the LLM service. The LLM reads this context and generates an accurate, focused answer based on your documents.
Generate answer using context
const answer = await llm.chat({
question: "What are neural networks?",
context: matches.map(m => m.text).join('\n')
});Streams back: “Neural networks are powerful algorithms that…”
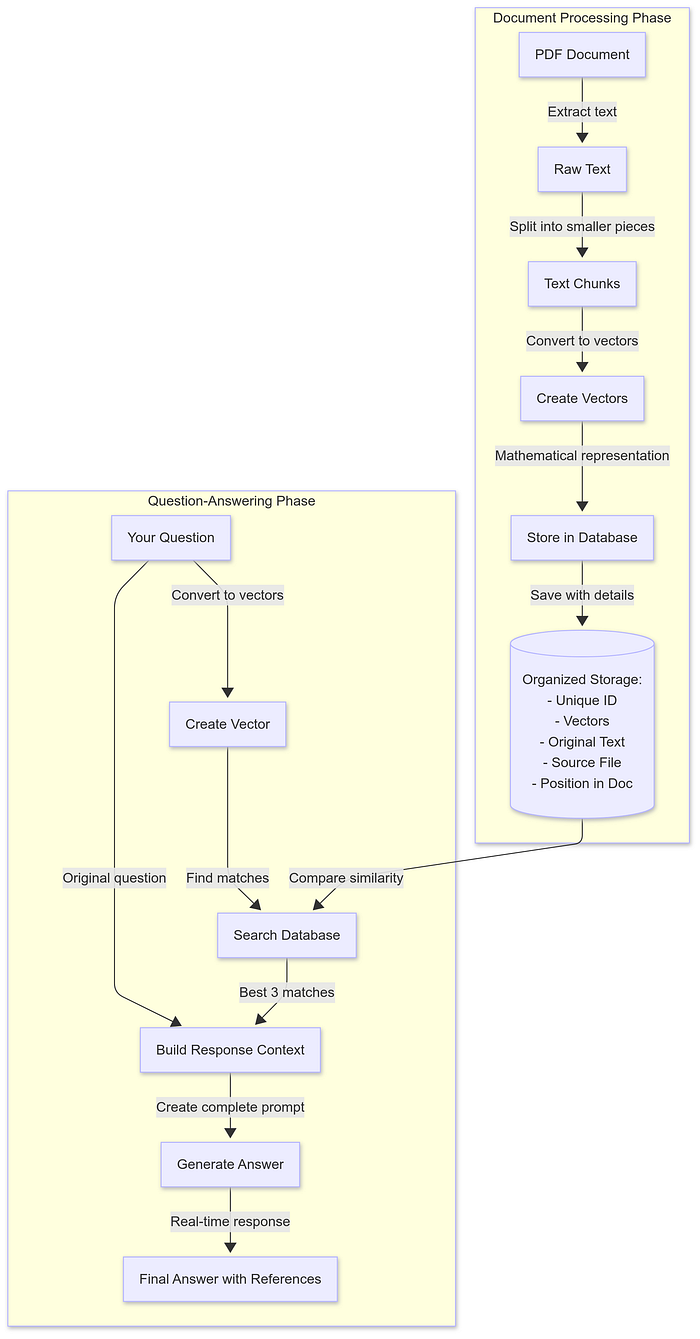
5. How It All Works Together
The system connects document processing and question answering in a seamless flow:
1. Document Processing:
- Read and parse PDF content using pdf-parse
- Split text into chunks using RecursiveCharacterTextSplitter (1000 chars with 200 char overlap)
- Generate vector embeddings for each chunk using the LLM API (3072-dimensional vectors)
- Store in Qdrant collections with rich metadata
- Create optimized Cosine similarity indices for efficient search
2. Question Answering:
- Convert user’s question into a vector using the same embedding model
- Search Qdrant for the most relevant chunks (default: top 3)
- Create a structured prompt combining: Retrieved context chunks, User’s question, Response guidelines (bullet points, markdown formatting)
- Send to LLM for final answer generation
- Stream the response back to the user with source references
For a smoother user experience, responses are streamed in real-time as they’re generated, with each chunk including both the answer and its source references. This provides immediate feedback while maintaining the accuracy and traceability of RAG systems.
System Flow Diagram:
Conclusion:
RAG gives AI systems the ability to have meaningful conversations about your documents, combining an AI’s natural understanding of language with specific information from your documents to create responses that are both intelligent and factually grounded.
A real-world example can be:
Working with an architect designing your dream house:
When you consult with the architect, they already know the fundamentals of house design and construction — just like how an LLM understands language and general concepts. But to create exactly what you want, you show them your inspiration: floor plans you like from different houses, photos of designs that inspire you, specific material choices you prefer, and layout diagrams that appeal to you.
The architect then:
Takes all these references and works their magic. They carefully review your materials, identify the elements that match your needs, and blend them with their expertise. The result is a design that’s not only personalized and structurally sound but also transparent — they can show you exactly how each part of the final design was inspired by your references. Just like our RAG system, the architect doesn’t make up designs from thin air, but rather combines and adapts from verified sources to create something perfect for you.
The more relevant references you provide, the better the architect can understand your vision and create exactly what you want
Similarly, our system uses vectors to identify and provide the most relevant context to the LLM, ensuring you get precise, well-informed answers from your documents.
You now have both the understanding and the practical knowledge to build a PDF chat system that can:
- Process a PDF document
- Find relevant information quickly
- Generate accurate, context-aware answers
Try out the library
You can find the complete implementation of this RAG system in our GitHub Repository, including all the code we’ve discussed in this guide, along with working examples using Express and NestJS frameworks.
About the Author: You can find more details about my projects and contributions on my website: msroot.me
Resources:
